
月之暗面近日开源了 checkpoint engine,这是一款专为大语言模型(llm)推理引擎打造的中间件,旨在强化学习等应用场景中实现模型权重的原地热更新。
该技术能够在大约 20 秒内完成拥有 1 万亿参数的 Kimi-K2 模型在数千张 GPU 上的权重同步,极大缩短了强化学习训练过程中因模型更新导致的停机时间。
目前,Checkpoint Engine 已深度集成于 vLLM 框架,其接口设计具备良好的扩展性,未来可便捷支持 SGLang 等其他主流...

蚂蚁集团百灵团队近日正式发布了ling 2.0系列的首个开源模型——ling-mini-2.0。该模型采用创新的moe架构,激活比例仅为1/32,总参数量达16b,但在处理每个token时仅激活1.4b参数(非embedding部分为789m),实现了高效计算与性能的平衡。
Ling-mini-2.0经过超过20万亿token数据的训练,并通过多阶段监督微调和强化学习技术,显著提升了复杂推理和指令遵循能力,整体表现可媲美7–8B级别的dense模型。
在多项权威评测中...
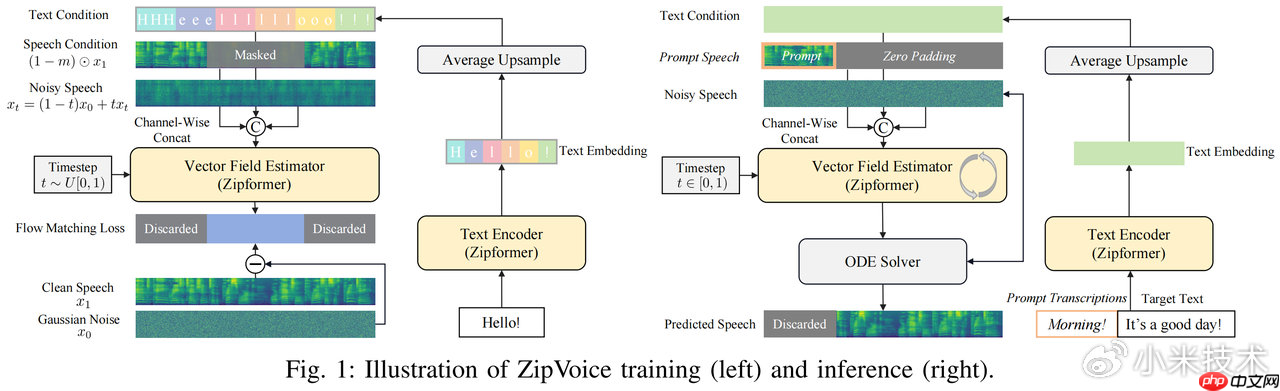
近日,小米集团新一代 Kaldi 团队推出了基于 Flow Matching 框架的 ZipVoice 系列语音合成(TTS)模型,包括 ZipVoice(零样本单人语音合成模型)和 ZipVoice-Dialog(零样本对话语音合成模型)。
作为 zipformer 架构在语音生成领域的延伸与实践,ZipVoice 有效缓解了当前零样本语音合成模型普遍存在的模型参数庞大、推理速度缓慢等问题,在模型轻量化与生成效率方面实现了显著提升。而 ZipVoice-Dialo...

阿里通义qwen团队近日推出了全新一代基础模型架构qwen3-next,并正式开源了基于此架构的qwen3-next-80b-a3b系列模型。
据悉,该架构在前代Qwen3的MoE结构基础上实现了多项关键升级,主要包括:
引入混合注意力机制
采用高稀疏度的MoE结构
集成多项有助于训练稳定的优化技术
加入提升推理效率的多token预测能力
Qwen3-Next被视为即将发布的Qwen3.5模型的前瞻版本,致力于增强大模型在超长上下文处理和大规模参数...

蚂蚁集团与中国人民大学携手推出业界首个原生moe架构的扩散语言模型(dllm)——llada-moe,成功在约20t数据上完成从零开始的大规模训练,充分验证了该架构在工业级应用中的扩展性与稳定性。该模型在性能上超越此前发布的稠密型扩散语言模型llada1.0/1.5和dream-7b,表现媲美同等规模的自回归模型,同时具备数倍推理速度优势。项目将于近期全面开源,助力全球ai社区推动dllm技术进步。
9月11日,在2025 Inclusion·外滩大会上,这一突破性成果...

论文地址: https://www.php.cn/link/5810733635b8629df4a4badaaef78f6c
由字节跳动智能创作团队与清华大学联合推出的 HuMo,是一个统一的 HCVG(Human-Centric Video Generation)框架,致力于推动以人为中心的视频生成技术发展。该框架支持文本、图像和音频三种模态的协同驱动,实现高度可控的人物视频生成。
HuMo(全称 Human-Modal)通过构建高质量多模态数据集,并引入创...
小红书团队近日开源了名为 FireRedTTS2 的全新语音合成系统,专为多说话人场景下的长篇流式对话生成设计,致力于为播客内容创作与智能聊天机器人提供更加自然、连贯的语音输出体验。
主要特性包括:
支持长文本多角色对话:可生成最长 3 分钟的四人对话内容,并具备良好的扩展性,通过增加训练数据即可支持更长时间的对话及更多说话人。
多语言能力强大:系统覆盖英语、中文、日语、韩语、法语、德语和俄语等多种语言,能够在跨语言交流或代码切换语境下实现零样本语音克隆,无...

2025年,“智能体元年”的说法频频被提及——大模型技术突飞猛进,各类智能体应用层出不穷,一场由ai智能体驱动的产业变革是否已悄然开启?
9月11日,在2025 Inclusion·外滩大会“智能体时代进化论”见解论坛上,来自学术界与产业界的多位专家围绕这一话题展开了深入探讨。本次论坛由硅谷101、特工宇宙与蚂蚁集团联合主办,硅星人担任特邀主持,议题涵盖智能体的技术突破、多智能体协同、开源生态构建以及垂直场景落地,直面当前行业高涨期待背后的现实挑战。
技术进展亮眼,多...

微软正大力投入资源,提升用于训练自主AI模型的服务器基础设施。在一次公司内部会议上,微软AI负责人穆斯塔法・苏莱曼透露,公司正在对下一代前沿AI模型展开“大规模投资”。他表示:“我们必须拥有自主研发世界级先进模型的能力,覆盖从轻量级到超大规模的各类模型。同时,在合适的情况下,也应合理利用外部模型资源。” 这一表态凸显了微软力争在人工智能领域与Meta、谷歌以及xAI等科技巨头同台竞技的战略意图。
目前,微软已着手建设专属的高性能计算集群。现阶段,MAI-1-prev...

9 月 13 日,在 2025 inclusion·外滩大会的ai开源见解论坛上,蚂蚁开源携手inclusion ai正式推出了《全球大模型开源开发生态全景与趋势报告》2.0版本。
相较今年5月发布的初版,此次更新全面反映了过去百余天内开源社区的最新动态,系统梳理了人工智能开源生态的发展现状与未来走向,为技术从业者和产业界提供了权威参考。
(蚂蚁开源技术委员会副主席王旭现场解读全球大模型开源生态发展态势)
蚂蚁开源技术委员会副主席王旭表示:“我们以数据为基础,真...