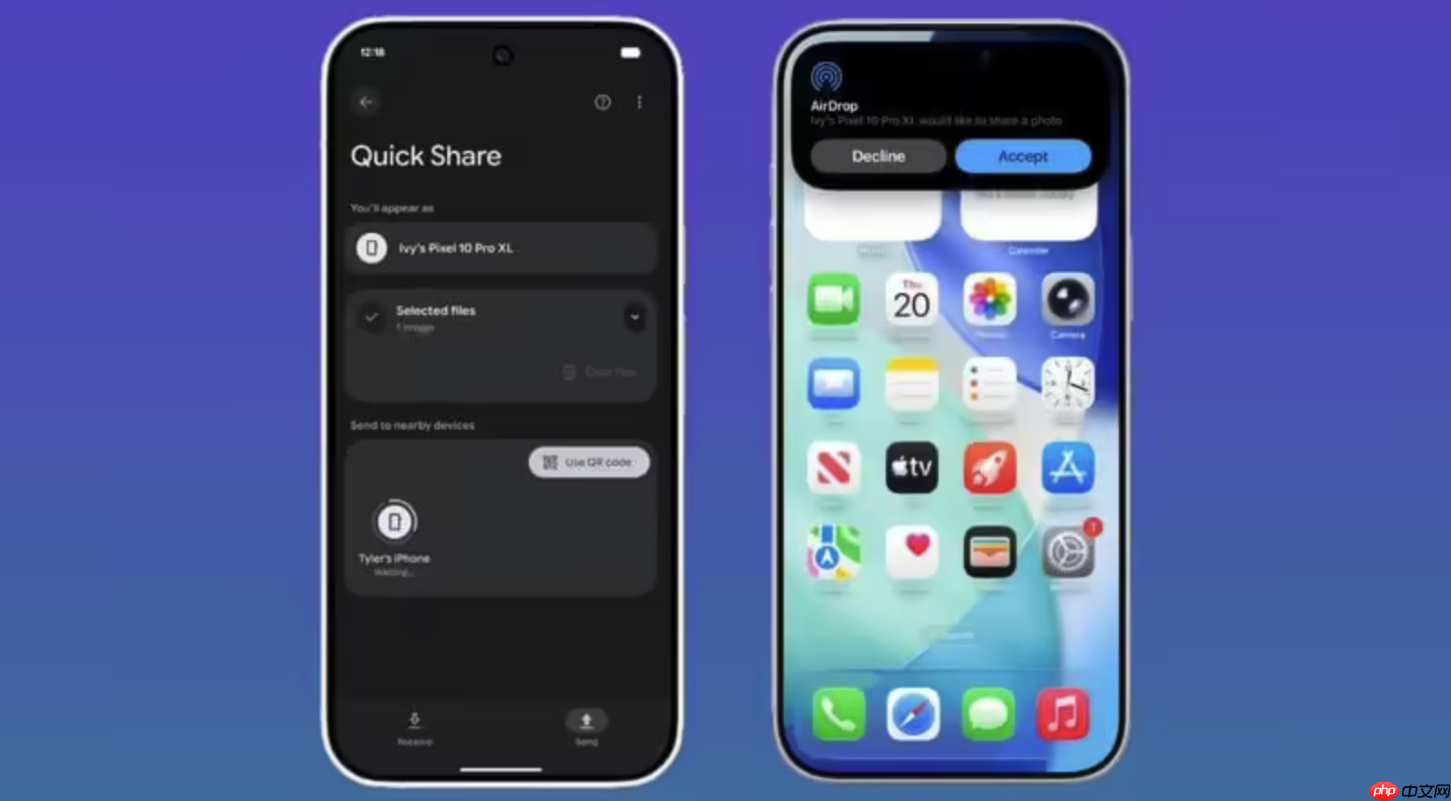
谷歌近日在Pixel 10系列智能手机上实现了安卓“快速分享”(Quick Share)与苹果“隔空投送”(AirDrop)的跨平台互通,标志着两大主流移动操作系统首次达成原生文件互传的重大突破。这一功能允许用户在安卓设备与iPhone、iPad及Mac之间直接传输照片、视频和文档,无需依赖第三方应用或云服务。
该消息迅速引发科技行业广泛关注。然而,与此前谷歌和苹果在RCS短信、未知追踪器警报等项目上的联合协作不同,此次苹果对合作始终保持沉默,并未公开确认参与其中。...
在辉达(nvidia)即将发布第三季财报之际,市场关于ai是否存在泡沫的讨论愈演愈烈。然而,执行长黄仁勋(jensen huang)在财报电话会议上明确否定了这一观点,坚定表示:「许多人正在谈论ai泡沫。但从我们的视角来看,现实情况完全不同。」
投资人关注数据 风险疑虑升温
近期,在辉达公布财务业绩前,投资者纷纷担忧当前AI热潮是否已脱离实际需求。特别是各大企业争相投入巨资建设AI数据中心,引发对未来能否实现足够回报的质疑。
尽管外界预期黄仁勋会为公司立场辩护——...
11月18日,消息指出nvidia凭借其ai显卡在人工智能时代脱颖而出,成为最大受益者。最新发布的财报再次显示,其产品依旧处于全球抢购的供不应求状态。
尽管GPU市场上竞争者众多,但在AI专用GPU领域,目前尚无厂商能真正与NVIDIA抗衡。这不仅归功于其硬件性能的领先,更在于CUDA生态系统的强大优势——这一点已被反复提及。
那么,CUDA究竟强在哪里?技术细节暂且不谈,不妨来看看NVIDIA官方如何回应。
在最近一次财报会议上,NVIDIA首席财务官Colett...
11月21日,针对谷歌、亚马逊等科技巨头纷纷布局定制化ASIC芯片的举动,英伟达CEO黄仁勋回应称,全球范围内能完成类似NVIDIA复杂工程的团队寥寥无几。
在讨论大型科技企业内部开发AI专用芯片的挑战时,黄仁勋并不认为这些项目会对英伟达构成实质性威胁。他解释道,真正能够构建出如此“极端复杂系统”的工程团队极为稀缺。
黄仁勋特别强调,NVIDIA拥有一支规模庞大且高效敏捷的团队,这种人才优势是竞争对手难以复制的核心壁垒,也是他不将ASIC视为重大竞争风险的关键原因...
11 月 21 日消息,科技媒体 Wccftech 昨日(11 月 20 日)发布文章指出,在最新财报电话会议中,针对谷歌、亚马逊等大型科技企业自研 ASIC 芯片所带来的竞争压力,英伟达 CEO 黄仁勋作出了公开回应。
据该报道,随着谷歌推出 TPU、亚马逊推出 Inferentia 等专用芯片,业内对其是否能在 AI 领域挑战英伟达主导地位的讨论持续升温。特别是在 AI 工作负载逐渐从“训练”转向“推理”的背景下,有观点认为英伟达的硬件优势可能被削弱。
对此,...
随着谷歌gemini 3 pro等一系列新模型的发布,并在ai圈内掀起热潮,“昔日风向标”openai正感受到前所未有的压力。
一份最新曝光的OpenAI内部备忘录显示,其CEO萨姆·奥特曼已于上个月向公司内部员工坦承:“谷歌最近在AI方面的进展,可能会给我们公司带来一些暂时的经济阻力。”
据悉,在奥特曼发表这番言论时,OpenAI的研究人员已经知晓,谷歌开发的一款新模型(即Gemini 3),在多项能力上已超越了OpenAI的现有模型。这间接承认了,OpenAI...
11月24日消息,曾经的bat三巨头中阿里、腾讯在游戏或者云服务领域业绩良好,百度则被外界认为还在依靠传统搜索业务,然而最新报告显示百度其实被低估了。
大摩日前发布了一份报告,上调了百度的目标股价到188美元,相比目前有70%的增长空间,看好百度的理由就是其转型AI的速度和规模都被低估了,明年就会有一波爆发。
大摩预测百度自研的AI芯片收入将从今年的13亿元暴涨到明年的83亿元,增长6倍之多,带动百度的GPU计算收入在2026年翻倍。
百度也已经明确转向AI优先的业...
anthropic 推出了其最新旗舰级模型 claude opus 4.5,重点提升了在工程能力、长周期任务处理以及智能代理(agent)执行效率方面的表现,旨在成为“软件开发、系统操作与自动化流程”领域中最强大的通用人工智能模型之一。
工程能力与性能全面跃升
在多个软件工程基准测试中表现卓越,尤其在复杂编码任务和长链条逻辑推理方面实现显著突破。
针对长时间对话、多步骤工具调用及代理式任务执行进行了深度优化,能够稳定支持持续数小时乃至跨日运行的复杂...
过去两年,大模型技术在全球范围内经历了迅猛发展,而 deepseek 的崛起彻底重塑了行业的技术路线、成本结构以及对开源生态的认知。从 2024 年初到 2025 年,其系列模型在性能表现、推理能力与工程效率方面实现了显著跃迁。从最初的 deepseek-llm 起步,历经 v2 阶段大规模 moe 架构的探索,再到 v3 与 r1 在性能和推理机制上的重大突破,deepseek 已成为引领开源大模型迈向高性能、低成本时代的关键推动力。
进入 2025 年后,Dee...
amd联合ibm及ai新锐zyphra推出zaya1——全球首款完全基于amd硬件训练的moe基础模型,完成14t tokens预训练,整体表现媲美qwen3系列,数学与stem推理能力在未进行指令微调的情况下已接近qwen3专业版本。
训练配置
集群架构:IBM Cloud平台部署128节点,每节点搭载8块AMD Instinct MI300X,总计1024张加速卡;采用InfinityFabric互联技术与ROCm软件栈,实现峰值算力750PFLOPs
训练...