
阿里云正式推出 qwen3-omni,宣告全球首个原生端到端全模态 ai 模型的诞生,该模型现已全面开源。qwen3-omni 能够无缝处理文本、图像、音频和视频等多种输入形式,并支持实时流式输出,无论是通过文字还是自然语音交互,均可实现快速响应与高效反馈。
在多项跨模态任务中,Qwen3-Omni 展现出了卓越的性能表现。依托早期以文本为中心的预训练策略以及混合多模态联合训练机制,模型在保持文本与图像处理高水准的同时,在音频和视频理解方面尤为突出。根据涵盖36项音...

在语音合成技术快速发展的背景下,面壁智能与清华大学深圳国际研究生院人机语音交互实验室(thuhcsi)近日联合发布了一款新型语音生成模型 ——voxcpm。这款模型以0.5b 的参数尺寸,致力于为用户提供高质量、自然的语音合成体验。
VoxCPM 的推出标志着高拟真语音生成领域的又一里程碑。该模型在自然度、音色相似度及韵律表现力等关键指标上,均达到了行业领先水平。通过零样本声音克隆技术,VoxCPM 能够以极少的数据,生成用户独特的声音,从而实现个性化的语音合成。这一技...

aibase报道 - 阿里巴巴旗下ai图像处理工具qwen-image近期推出重磅功能更新,最受关注的是全新上线的多图编辑能力,为电商与数字营销领域提供了颠覆性的内容创作方案。
多场景融合编辑实现突破
最新版本Qwen-Image-Edit-2509现已支持多种图像协同编辑模式,涵盖人物+人物、人物+商品、人物+背景等多样化组合方式。用户可便捷地合成合影、构建场景画面或打造高水准的产品宣传图,全面适配电商平台展示与广告推广的复杂需求。
根据官方发布的实际演示效果,该工...

【AIbase 报道】根据 Radware 安全团队的最新发现,人工智能对话平台 ChatGPT 所搭载的“深度研究”功能曾暴露出一个高危漏洞,代号为“ShadowLeak”。该漏洞可被恶意利用,导致用户的 Gmail 账户信息(如姓名、地址等敏感数据)在未授权且无感知的情况下被窃取。
此次攻击的独特之处在于,整个过程完全在 OpenAI 的云端环境中进行,不留外部入侵痕迹,同时能有效规避本地防火墙和其他终端防护机制。研究人员形象地将这种被操控的 AI 代理称为“由...

近日,中国科学院自动化研究所李国齐与徐波领衔的科研团队正式推出全球首个大规模类脑脉冲大模型——spikingbrain1.0。该模型在处理超长文本方面表现卓越,能够以超过现有主流 transformer 模型百余倍的速度完成400万 token 的文本处理任务,同时仅需其2%的训练数据量。
目前广泛应用的大语言模型,如GPT系列,大多依赖于Transformer架构。尽管其自注意力机制具备强大的语义捕捉能力,但随之而来的高计算复杂度成为显著瓶颈。当输入文本长度增加时...

近日,阿里云重磅宣布通义万相全新动作生成模型 wan2.2-animate 正式开源,此举有望为短视频创作、舞蹈模板生成以及动漫制作等行业注入全新动力。开发者和创作者可通过 github、huggingface 及魔搭社区免费获取该模型及其完整代码。同时,用户还能通过阿里云百炼平台调用其 api,或直接访问通义万相官网在线体验模型的强大能力。
Wan2.2-Animate 是在前代模型 Animate Anyone 的基础上实现全面进化的成果,在人物一致性、画面清晰...

2025年9月19日,阿里云正式宣布通义万相推出全新动作生成模型——wan2.2-animate,并全面开源。该模型可驱动人物、动漫形象及动物图片实现动态化,广泛适用于短视频创作、舞蹈模板生成、动画制作等场景。开发者和创作者可通过 github、huggingface 以及魔搭社区免费下载模型权重与代码,也可通过阿里云百炼平台调用 api,或直接在通义万相官网进行在线体验。
作为此前开源项目 Animate Anyone 的全面升级版本,Wan2.2-Animate 在...
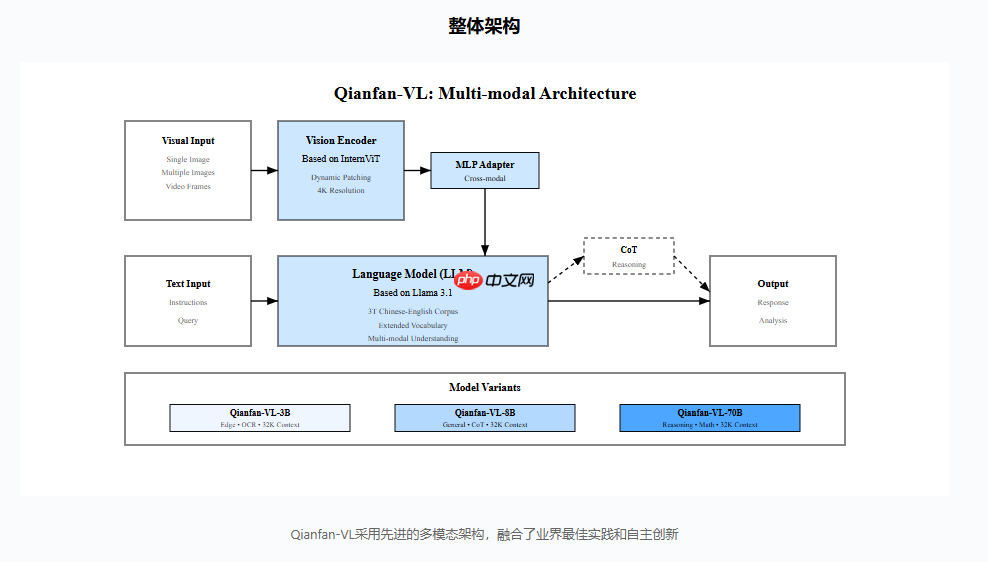
百度智能云千帆团队近日正式推出了全新视觉理解模型 Qianfan-VL,并宣布全面开源!该系列涵盖3B、8B 和70B 三种不同参数规模的版本,专为满足企业级多模态应用需求而设计。经过深度优化,模型在视觉理解方面展现出卓越的能力。
Qianfan-VL 不仅具备强大的基础性能,还针对行业高频应用场景进行了重点增强,特别是在光学字符识别(OCR)和教育领域表现突出,显著提升了实际使用中的效果。该模型基于开源架构研发,并在百度自研的昆仑芯 P800 平台上完成全链路...

在刚刚落幕的华为全联接大会上,华为技术有限公司携手浙江大学共同发布了国内首款基于昇腾千卡算力平台打造的基础大模型——DeepSeek-R1-Safe。该模型聚焦当前人工智能领域中的安全与性能难题,标志着我国在AI安全技术研发方面迈出了关键一步。

浙江大学计算机科学与技术学院院长任奎现场深入解读了该模型的技术亮点。他表示,DeepSeek-R1-Safe 采用了一套完整的安全后训练框架,涵盖高质量安...

开源直播与录制软件 obs studio 32.0.0 正式上线,此次版本更新带来了多项重要功能与优化,包括内置插件管理器、windows 与 macos 平台可选的自动崩溃日志上传、对 nvidia rtx 语音活动检测及背景移除中“椅子去除”功能的支持,并为 apple silicon 设备新增了实验性的 metal 渲染器支持。
本次发布的主要亮点如下:
集成插件管理器: 新增原生插件管理功能,用户可更便捷地安装、更新和管理插件,无需再手动复制文件至指定目...