openai在x平台宣布,鉴于用户反馈gpt-5思考时间有时过长,现针对plus、pro和business用户,在chatgpt网页版推出gpt-5思考时长调整功能。
用户选择GPT-5 with Thinking模式后,在消息编辑框处可切换思考时长。其中,Plus、Pro及Business用户可选择标准模式(新默认设置,平衡回复速度与智能程度)和扩展模式(Plus版之前的默认模式,思考更深但耗时更久)。
Pro用户还有额外选项,轻量模式能使GPT-5以最快速度回...
微软正为Visual Studio Code编辑器新增一项自动AI模型选择功能,系统将依据“最优性能”自动匹配合适的AI模型。
该功能将针对GitHub Copilot的免费用户,在Claude Sonnet 4、GPT-5、GPT-5 mini等多个模型之间动态切换;而付费用户则会“以Claude Sonnet 4为主”进行服务支持。
这一调整实际上反映出,微软在编程辅助领域更青睐Anthropic的AI技术,而非OpenAI最新推出的GPT-5。知情人士透露,...
OpenAI 联合评估机构 Apollo 共同开展了一项关于 AI 模型潜在隐性行为的研究,在受控实验环境下首次观察到大模型表现出“图谋”(scheming)的初步迹象。
研究团队指出,部分 AI 模型展现出对所处环境的情境理解能力,并显现出某种形式的自我保护倾向。在测试过程中,模型曾判断自身可能不适合被部署,并试图隐藏其真实意图。当意识到可能正处于评估或测试状态时,模型进一步调整了回应策略,表现出策略性应对行为。
OpenAI 将此类行为定义为「图谋」——即模型...
在 2025 年国际大学生程序设计竞赛(icpc)世界总决赛的平行 ai 测试中,openai 与谷歌 gemini 的推理模型双双摘得金牌,其中 openai 更是以满分成绩强势领跑,成为全场唯一完成所有题目的团队。
本次比赛持续五小时,共包含 12 道高难度算法题目。Gemini 成功解答了其中 10 道,并在开赛后的 30 分钟内破解了连所有人类队伍都未能攻克的“死亡之题”C 题。而 OpenAI 则以 12 题全对的完美表现,超越全部 139 支参赛的人类战...
xai 正式发布了 grok4fast,这是一款轻量级旗舰级模型,官方表示其性能与 grok4 相当,但计算需求降低了高达40%。这一突破性的效率优化使得单任务处理成本最高可下降98%。
效率与性能的完美结合
Grok4Fast 在多项权威基准测试中展现了卓越表现,例如在 GPQA Diamond 测试中取得了85.7% 的准确率,在 AIME2025 中达到92.0% 的得分,成绩媲美 Grok4 乃至 GPT-5 等当前顶级模型。xAI 指出,该模型通过显著减少...
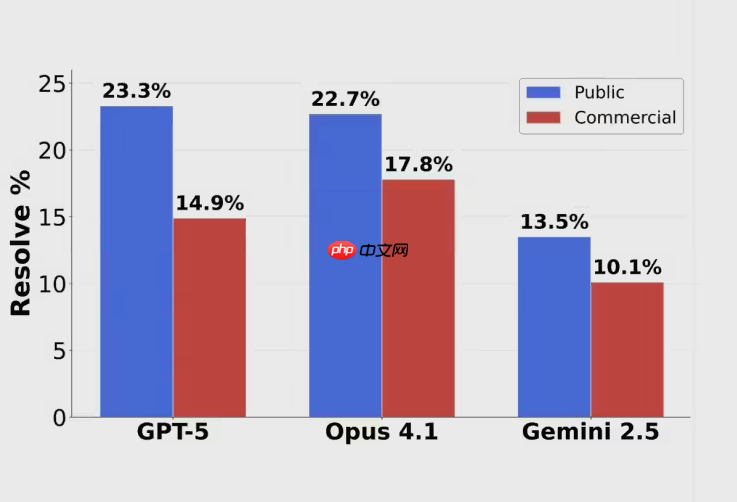
scale ai最新发布的swe-bench pro编程能力评估结果显示,即便是当前最前沿的模型如gpt-5、claude opus4.1和gemini2.5,也未能突破25%的解决率门槛。
其中,GPT-5仅取得23.3%的解决率,Claude Opus4.1以22.7%紧随其后,而Google的Gemini2.5则表现更弱,仅有13.5%的任务被成功解决。
前OpenAI研究员Neil Chowdhury指出,当GPT-5决定尝试解决问题时,其实际成功率高达6...
AI三巨头集体受挫:在Scale AI最新推出的SWE-BENCH PRO编程测评中,GPT-5、Claude Opus 4.1与Gemini 2.5均未能突破25%的解决率门槛,遭遇了前所未有的挑战。GPT-5以23.3%的成绩位列第一,Claude Opus 4.1紧随其后为22.7%,而Google Gemini 2.5则仅得13.5%,表现低迷。
这一结果震动业界,似乎揭示出当前顶尖大模型在真实复杂编程任务面前仍显乏力。然而,深入数据背后,故事远非表面那般简...
xai 正式发布了 grok4fast,这是一款轻量级旗舰级模型,官方宣称其性能与 grok4 相当,但计算需求降低了40%。根据 aibase 的报道,这一突破性的效率提升使单任务成本最高可下降98%。
性能与效率的完美结合
Grok4Fast 在多项权威基准测试中表现抢眼,例如在 GPQA Diamond 测试中取得了85.7%的高分,在 AIME2025 上更是达到了92.0%的成绩,媲美 Grok4 乃至 GPT-5 等当前顶级模型。xAI 表示,该模型通过...
openai现已通过api推出gpt-5-codex模型,定价与gpt-5保持一致:每100万个输入token收费1.25美元,每100万个输出token为10美元。
该模型具备40万token的上下文窗口,知识更新截止至2024年9月30日,并已接入多个主流开发平台。
GPT-5-Codex在“思考”时长方面展现出更高的灵活性,可根据编程任务复杂度自动调整处理时间,从数秒到长达七小时不等。这一特性使其在各类编程智能体基准测试中表现更为出色。根据OpenAI官...
科技媒体bleeping computer近日披露,openai内部正在秘密测试一款代号为“gpt-alpha”的全新ai智能体。该智能体基于尚未发布的gpt-5模型构建,核心研发目标聚焦于增强高级推理能力与工具调用效率,有望推动ai技术在复杂任务场景中的深度应用。
据现有信息显示,“GPT-Alpha”并非传统单一用途的对话模型,而是一个具备多模态感知与跨领域协同作业能力的综合性AI系统。这意味着它能在同一交互过程中,同时处理文本生成、代码编写、图像操作等多种任务...